
Medical imaging is an information processing technique that takes data samples from medical devices such as magnetic resonance imaging (MRI) or computer tomography (CT) scanners and translates them into 2D, 3D or even 4D images. Advances in sensor technology allow for the generation of an increasing number of images per procedure and per patient, posing a tremendous challenge for the efficient, in-time processing and visualization of the resulting images. In addition, sensor systems are now capable of acquiring thousands of projections per second, literally flooding the image reconstruction subsystem with several hundreds of Mbytes of data per second.
CT is used in a growing number of clinical applications, and keeps challenging the scientific community to continuously propose new algorithms with improved image quality while reducing the X-ray dose. With modern algorithms, every single voxel in the reconstructed volume requires hundreds of processing cycles on a given processor. Combining the processing requirements with the high-input data rate, CT also challenges manufacturers to design computer systems that enable the object to be reconstructed within a time-frame compatible with the workflow in a hospital, while keeping costs reasonable. The implied tradeoffs have often led to the use of approximate methods such as Feldkamp-type algorithms for flat panel, detector-based systems used in C-arm CTs or micro-CT. However, keeping the reconstruction times acceptable has also forced the design of special-purpose reconstruction platforms based on field-programmable gate arrays (FPGAs) or application-specific integrated circuits (ASICs).
The Cell Broadband Engine Processor
Originally developed for the gaming industry by IBM, Toshiba and Sony, the industry-leading Cell microprocessor technology is under development for use in medical, defense, and commercial applications, mainly because the Cell technology offers significant performance improvement compared to other available technologies. The Cell Broadband Engine (CBE) architecture is essentially a multi-computer-on-a-chip, representing the integration of multiple processor cores on a single die. The CBE consists of one IBM 64-bit Power Architecture core, called the power processing element (PPE), and eight specialized co-processors called synergistic processing elements (SPEs). The PPE can be considered as an implementation of a PowerPC processor with the traditional hardwired L1 and L2 caches. The SPEs are oriented toward parallel vector processing, using a novel single-instruction, multiple-data (SIMD) operating architecture.
The SPEs do not possess traditional cache hardware. Instead, multiple levels of memory hierarchy must be explicitly managed by software. All nine cores in the CBE are interconnected by a coherent on-chip element interconnect bus (EIB). The EIB also connects to the memory controller, the I/O interface and the coherence interface. The memory controller and the I/O interfaces give all processing elements access to main memory and I/O space while the coherence interface allows for building multiprocessor systems in symmetric multiprocessor mode. The Cell architecture enables all kinds of distributed applications to run on the processing units, using elaborate data-transfer techniques to design any combination of parallel/pipelined approaches. Therefore, all applications that have the ability to subdivide the main tasks can be subdivided into a finite number of subtasks, and take advantage of the immense processing power implemented in the Cell processing elements while keeping the data-transfer latency very low. Clocked at 3.2 GHz, the Cell processor offers a peak performance of 204.8 GFLOPS from the set of eight SPEs running, and a memory bandwidth of 25 Gbytes/s which is significantly higher than any off-the-shelf solution. The EIB is capable of peak data rates of ~200 Gbytes/s. This ground-breaking level of extreme performance, coupled with the vector processing capabilities of the SPEs, make the CBE capable of delivering dramatic new capabilities to embedded applications that rely upon computationally intense processes such as Fast Fourier Transforms (FFTs), matrix operations or backprojection algorithms.
The Cell Processor:
Challenging Software Development

The challenge of the CBE lies in the complexity of its design. Without software tools, this complexity puts a substantial burden on any programmer. To be suitable for broad use in embedded applications, the CBE needs a layer of software to help programmers distribute processing among multiple cores, as well as manage use of the multiple levels of memory. Mercury Computer Systems developed the MultiCore Framework (MCF), which provides an abstract view of CBE operations, oriented toward computation of multidimensional data sets. With MCF, the programmer has explicit control over how data and processing is divided among processor cores and memory elements while being insulated from specific hardware details. The key innovation in MCF is something called the data-distribution object, which is a way of describing an n-dimensional matrix data set in such a way that it can be processed in small chunks, or tiles, by one or more workers. For each data set, the manager program specifies a set of parameters for each distribution object, such as number of dimensions, size of dimensions, tile size, packing order and data types.
The manager program also specifies how data is partitioned across the worker programs and the level of multibuffering the MCF must implement to accommodate the processing latency of the application. In order to move tiles between the different stages in the processing pipeline, MCF implements the data movement through tile channels (Figure 1). This abstract object enables the user application to transfer tiles from one stage to the next, according to the partitioning policy and the defined level of multibuffering. In the simplest case, a manager defines two distribution objects, one for input data and one for results, and two corresponding input and output tile channels. Worker programs typically are very simple, consisting of a loop that reads input tiles, computes output data, and injects output tiles. MCF overlaps memory access with computation for maximum performance. Further, since MCF separates data organization from computation, problem size and resource allocation can be altered without changing worker programs. Medical image reconstruction, such as that found in CT, tomosynthesis, PET and SPECT, is computationally demanding. The Cell processor technology offers the advantages of a cost-effective, high-performance platform for medical reconstruction and imaging. Mercury is working with the Institute of Medical Physics (IMP) of Erlangen, Germany, to design and implement ambitious reconstruction and visualization algorithms with real-time performance on the CBE to deliver orders-of-magnitude performance increases while also reducing the complexity and costs of medical image processing systems. As an example of the joint work, Mercury and the IMP have developed a Cell BE processor-based solution capable of performing modern CT reconstruction more than 100 times faster than conventional microprocessors (Figure 2).
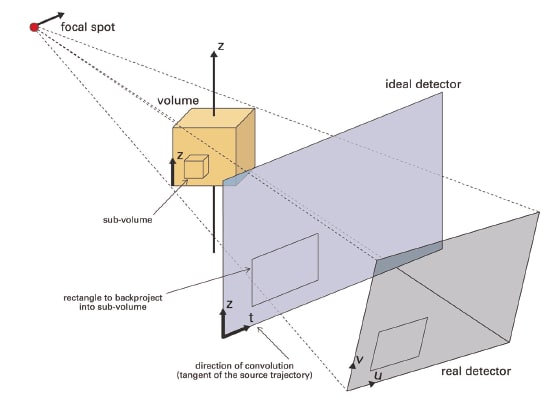
The level of parallelism, along with the vast I/O capabilities, permits the Cell BE processor to efficiently implement complex CT reconstruction algorithms with close to realtime performance. Basic medical image reconstruction consists of data weighting, convolution, and back-projection. The last step is the most demanding step during reconstruction. Fortunately, all image reconstruction steps can be parallelized quite easily by taking advantage of the Cell architecture. To assess back-projection performance, an implementation of a 3D perspective cone-beam back-projection algorithm was ported to the Cell processor, using MCF. Several constraints had to be followed. The SPE local store (LS) is limited to 256 KB and only small portions of the full problem can be handled by each SPE. To accommodate demand, the image and raw data (sinograms) were tiled into subimages and sub-sinograms. The subimage was defined as a small cube of 323 voxels. Only those portions of a projection that were needed for a particular sub-image comprise the sub-sinogram. The level of multibuffering was set to two. In this way, while the backprojection program is busy with the first subsinogram, MCF transfers the next sub-sinogram.
The data-transfer latency is fully hidden behind the backprojection processing. During optimization, care was taken to make use of the Cell processor’s 128 available registers per SPU to fully fill the execution pipelines. Manual loop unrolling and reordering of instructions ensured that a throughput of more than one instruction per clock cycle would be achieved. Vectorization was achieved by treating each quadruple of neighboring pixels as a 4-vector of floating-point values; therefore the number of pixels per row must be a multiple of four. Using one CBE for a flat-panel, detector- based system, such as C-arm CT or micro-CT, a back-project can be completed on a volume of 5123 voxels from 512 projections in 14 seconds. The performance can be doubled by using both CBEs available on a Dual Cell-Based Server. The time required for convolution and data reorganization prior to backprojection is in the order of 5% of the time required for backprojection and therefore negligible.
Cell and MCF:
Off-the-Shelf Solution for Embedded Applications
The performance achieved for conebeam CT with a Cell-processor-based architecture is a major breakthrough with off-the-shelf hardware. Cell-based systems deliver the processing power needed for affordable, high-performance medical imaging systems capable of living up to the requirements of modern detectors such as those designed for CT gantries and of delivering accurate data to the radiologist to make precise diagnostics. Indeed, the CBE processor proposes a new alternative to build a computer system capable of performing modern cone-beam CT reconstruction without hosting dedicated and expensive devices. The level of parallelism along with the vast I/O capabilities permits the Cell processor to efficiently implement complex CT reconstruction algorithms with close to real-time performance. The CBE enables systems to be designed where the radiologists can view images obtained from better algorithms, with higher quality, much sooner than ever before. Critical decisions can be made more rapidly and more accurately.
This article was written by Olivier Bockenbach, Senior Systems Engineer, Performance Computing Group, Mercury Computer Systems, Inc. (Berlin. Germany). For more information, contact Mr. Bockenbach at