
The cascade back-propagation (CBP) algorithm is the basis of a conceptual design for accelerating learning in artificial neural networks. The neural networks would be implemented as analog very-large-scale integrated (VLSI) circuits, and circuits to implement the CBP algorithm would be fabricated on the same VLSI circuit chips with the neural networks. Heretofore, artificial neural networks have learned slowly because it has been necessary to train them via software, for lack of a good on-chip learning technique. The CBP algorithm is an on-chip technique that provides for continuous learning in real time.
Artificial neural networks are trained by example: A network is presented with training inputs for which the correct outputs are known, and the algorithm strives to adjust the weights of synaptic connections in the network to make the actual outputs approach the correct outputs. The input data are generally divided into three parts. Two of the parts, called the "training" and "cross-validation" sets, respectively, must be such that the corresponding input/output pairs are known. During training, the cross-validation set enables verification of the status of the input-to-output transformation learned by the network to avoid overlearning. The third part of the data, termed the "test" set, consists of the inputs that are required to be transformed into outputs; this set may or may not include the training set and/or the cross-validation set.
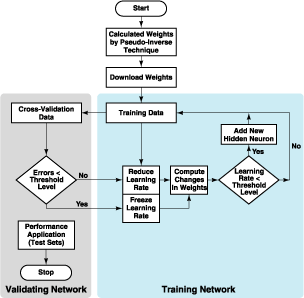
The CBP algorithm (see Figure 1) begins with calculation of the weights between the input and output layers of neurons by use of a pseudo-inverse technique. Then learning proceeds by gradient descent with the existing neurons as long as the rate of learning remains above a specified threshold level. When the rate of learning falls below this level, a new hidden neuron is added. When the quadratic error measure has descended to a value based on a predetermined criterion, the rate of learning is frozen. Thereafter, the network keeps learning endlessly with the existing neurons.
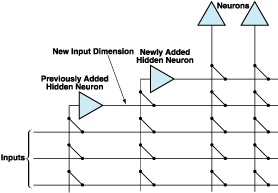
cascade aspect provides two important benefits: (1) it enables the network to get out of local minima of the quadratic error measure and (2) it accelerates convergence by eliminating the waste of time that would occur if gradient descent were allowed to occur in many equivalent subspaces of synaptic-connection-weight space. The cascade scheme concentrates learning into one subspace that is a cone of a hypercube.
The gradient descent involves, among other things, computation of derivatives of neuron transfer curves. The proposed analog implementation would provide the effectively high resolution that is needed for such computations. Provisions for addition of neurons at learning-rate-threshold levels could be made easily in hardware.
This work was done by Tuan A. Duong of Caltech for NASA's Jet Propulsion Laboratory. For further information, access the Technical Support Package (TSP) free on-line at www.nasatech.com/tsp under the Computers/Electronics category. This invention is owned by NASA, and a patent application has been filed. Inquiries concerning nonexclusive or exclusive license for its commercial development should be addressed to the Patent Counsel, NASA Management Office–JPL; (818) 354-7770. Refer to NPO-19289.
This Brief includes a Technical Support Package (TSP).

Cascade Back-Propagation Learning in Neural Networks
(reference NPO-19289) is currently available for download from the TSP library.
Don't have an account?
Overview
The document discusses the Cascade Back-Propagation (CBP) learning algorithm for artificial neural networks, developed by Tuan A. Duong at NASA's Jet Propulsion Laboratory. The CBP algorithm aims to accelerate the learning process of neural networks by implementing it in very-large-scale integrated (VLSI) circuitry, allowing for on-chip learning. This innovation addresses the slow learning rates of traditional artificial neural networks, which typically rely on software for training.
The CBP algorithm operates by first calculating the weights between the input and output layers of neurons using a pseudo-inverse technique. Learning then proceeds through gradient descent as long as the learning rate remains above a specified threshold. If the learning rate falls below this threshold, a new hidden neuron is added to the network. The process continues until the quadratic error measure reaches a predetermined criterion, at which point the learning rate is frozen, allowing the network to continue learning indefinitely with the existing neurons.
The document highlights the cascade aspect of the CBP algorithm, which provides two significant benefits: it helps the network escape local minima of the error measure and accelerates convergence by focusing learning in a single subspace of synaptic connection weights. This is achieved by adding new hidden neurons that receive inputs not only from the original input layer but also from previously added hidden neurons, enhancing the network's capacity to learn complex patterns.
Additionally, the input data for training the neural network is divided into three parts: a training set, a cross-validation set, and a test set. The training and cross-validation sets contain known input/output pairs, while the test set includes inputs that need to be transformed into outputs. The proposed circuitry for on-chip learning consists of two distinct networks—one for training and one for validation—sharing the same synaptic weights, which are continuously adjusted according to the CBP algorithm.
The document concludes by noting that this work is patented by NASA and encourages inquiries regarding commercial development. The CBP algorithm represents a significant advancement in the field of neural networks, promising faster and more efficient learning processes through its innovative on-chip implementation.