
A method for reducing the number of bits of quantization of synaptic weights during training of an artificial neural network involves the use of the cascade back-propagation learning algorithm. The development of neural networks of adequate synaptic-weight resolution in very-large-scale integrated (VLSI) circuitry poses considerable problems of overall size, power consumption, complexity, and connection density. Reduction of the required number of bits from the present typical value of 12 to a value as low as 5 could thus facilitate and accelerate development.
In this algorithm, neurons are added sequentially to a network, and gradient descent is used to permanently fix both the input and output synaptic weights connected to each added neuron before proceeding further. Each added neuron has synaptic connections to the inputs and to the output of every preceding neuron; thus, each added neuron implements a hidden neural layer. The addition of each successive neuron provides an opportunity to further reduce the mean squared error. Because the average number of connections to a neuron is small, learning is quite fast.
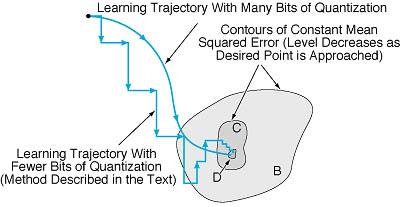
To adapt the cascade back-propagation algorithm to neural-network circuitry with limited dynamic range (equivalently, coarse weight resolution) in the synapses, one reduces the maximum synaptic conductances associated with neurons added later. This effectively reduces the sizes of synaptic-weight quantization steps, so that in the later stages, the desired synaptic-weight resolution is ultimately achieved and the learning objective approached as closely as required, without having to increase the number of bits (see figure).
Both simulations and tests with analog complementary metal oxide/semiconductor (CMOS) VLSI hardware have shown that by use of this method, neural networks can learn such difficult problems as 6-bit parity with synaptic quantizations as low as 5 bits, as opposed to the 8 to 16 bits required in the older error-back-propagation and cascade-correlation neural-network-learning algorithms.
This work was done by Tuan A. Duong of Caltech for NASA's Jet Propulsion Laboratory. NPO-19565
This Brief includes a Technical Support Package (TSP).

Training neural networks with fewer quantization bits
(reference NPO19565) is currently available for download from the TSP library.
Don't have an account?
Overview
The document is a NASA Technical Support Package detailing a novel methodology for training neural networks with fewer quantization bits, specifically aimed at improving efficiency in hardware implementations. The report, associated with JPL & NASA Case No. NPO-19565, addresses the challenges faced in conventional neural network architectures, particularly in terms of size, power consumption, and the complexity of input data.
Traditional learning algorithms often rely on fixed architectures, which can lead to inefficiencies. The proposed methodology introduces a flexible architecture that evolves from a simple two-layer precursor. This architecture allows for the dynamic addition of "hidden units" (neurons) as needed, enabling the network to adapt to the complexity of the task at hand. The Cascade BackPropagation (CBP) learning algorithm is central to this approach, featuring several key attributes: it adjusts step sizes dynamically with the addition of hidden units, improves system energy efficiency, and allows for easy adjustments of neuron inputs through weight values and biases.
One of the significant challenges in implementing neural networks in Very-Large-Scale Integration (VLSI) hardware is the requirement for high-resolution synaptic weights, typically around 12 bits. This high resolution complicates the design due to increased size and power consumption. The document suggests that reducing the quantization resolution to as low as 5 bits can still maintain adequate performance while alleviating these constraints.
The report also highlights the importance of parallel processing capabilities in solving computation-intensive problems such as vision, pattern recognition, and speech recognition. By leveraging the proposed flexible architecture and reduced quantization, the methodology aims to enhance the speed and efficiency of neural network training, making it more suitable for real-time applications.
In summary, this document presents a promising approach to neural network training that emphasizes adaptability and efficiency, potentially transforming how neural networks are implemented in hardware. The innovative techniques discussed could lead to significant advancements in various fields requiring high-speed processing and effective learning algorithms.