
An improved method of parallel computation of the electromagnetic-scattering characteristics of complexly shaped objects has been devised. This method belongs to a class of methods that involve the finite-element solution of Maxwell's equations on unstructured grids. ("Unstructured grids" in this context does not signify grids that lack structure; instead, it is a specialized term for grids with arbitrarily specified, complex, and/or irregular structures.) As explained below, the present method effects a simplification (relative to the older methods in the same class) in the use of parallel computers, and involves an algorithm that is scalable in the sense that it is readily useable on large, massively parallel computers. A finite-element mathematical model is needed to represent a typical electromagnetic-scattering structure that includes components made of various electromagnetically penetrable (e.g., dielectric) and/or impenetrable (electrically conductive) materials. An unstructured grid is needed to represent the complexity of the geometry of such a structure and its components. In the present method as in the other methods of the same class, the computational grid or mesh for a given problem must be truncated at a surface that surrounds the scattering structure at a suitable distance. The surface must be chosen consistently with the need to both maintain accuracy of the computed electromagnetic field and limit the meshed volume of free space. Maxwell's equations for the electromagnetic field are put in three-dimensional Helmholtz wave-equation form and solved on the mesh by a coupled finite-element/integral-equation technique.
The specific integral-equation formulation is of a boundary-element type. This formulation results in efficient and accurate truncation of the computational domain. A system of equations in partitioned-matrix·partitioned-vector form results from the combination of (1) finite-element discretization of the volume in and around the scattering structure and (2) integral-equation discretization of the surface. The system of equations is solved by a combination of (1) an iterative sparse-matrix-equation-solving subalgorithm and (2) a dense-matrix-factorization subalgorithm. The assembly and solution of the matrix equation and the computation of observable quantities are all accomplished in parallel, using various numbers of processors at various stages of the calculation.
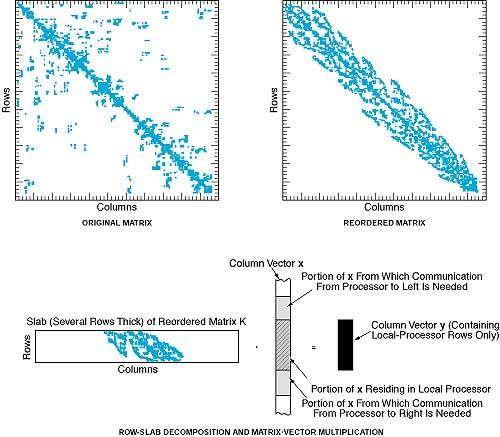
A common feature of the older methods is the need for mesh-partitioning algorithms to distribute the unstructured mesh and the sparse matrix entries among the available processors. This need arises from the distributed-memory architecture of typical parallel computers and the consequent lack of direct access, by every processor, to all the mesh and matrix data. In the present method, one does not explicitly partition the mesh; instead, one emphasizes decomposition of the sparse matrix entries among the processors, and such mesh partitioning as happens to occur becomes merely incidental to this decomposition. The choice of a specific decomposition is guided by recognition that what one needs to compute efficiently at each step of the iterative subalgorithm is the inner product of a sparse matrix and a dense vector.
The chosen decomposition is of a row-slab type. The figure illustrates aspects of the row-slab decomposition for an example problem. The top left part of the figure shows the original structure of the sparse matrix. The top right part of the figure shows the structure of the matrix as reordered for minimum bandwidth in preparation for the row-slab decomposition and the resulting matrix·vector multiplication Kx = y. Each processor handles one slab. Because of the minimum-bandwidth reordering, the minimum and maximum column indices of each slab are known. If the row indices of that piece of the dense vector x that is local to this processor contain the range from the minimum to the maximum column index for this slab, then the multiplication can be done purely locally, and the corresponding part of the product vector y will be purely local. In general, the column indices range beyond the local row indices; this gives rise to a need for a communication step to obtain the adjacent portions of x that are not local to this processor. This communication step involves data from a few processors to the left and right. The number of processors communicating data depends on the row bandwidth of the slab and the number of processors in use. Overall, the row-slab decomposition strikes a balance among (1) nearly perfect balance of data and computational load among processors, (2) minimal albeit suboptimal communication of data in the matrix·vector multiplication, and (3) scalability to larger problems on greater numbers of processors.
This work was done by Tom Cwik, Cinzia Zuffada, and Vahraz Jamnejad of Caltech for NASA's Jet Propulsion Laboratory. NPO-20171
This Brief includes a Technical Support Package (TSP).

Improved parallel computation of electromagnetic scattering
(reference NPO20171) is currently available for download from the TSP library.
Don't have an account?
Overview
The document presents an innovative method for parallel computation of electromagnetic scattering characteristics, particularly for complexly shaped objects. Developed by a team from NASA's Jet Propulsion Laboratory, this method leverages finite-element solutions of Maxwell’s equations on unstructured grids. Unstructured grids are defined as grids with complex and irregular structures, allowing for more accurate modeling of geometrically intricate objects, whether they are penetrable or impenetrable.
The introduction emphasizes the significance of large-scale parallel computation in engineering and scientific applications. The ability to utilize distributed memory machines with substantial memory capacity and computational speed enables the simulation of complicated engineering components. The document highlights the importance of achieving a significant fraction of the machine's peak performance while minimizing the costs associated with porting or developing code for parallel systems. This is particularly relevant for unstructured mesh simulations, which are essential for accurately capturing the electromagnetic fields scattered by complex materials.
The proposed method simplifies the parallelization process compared to older techniques, making it more accessible for implementation on large, massively parallel computers. The algorithm is designed to be scalable, ensuring that it can efficiently handle the demands of extensive computations required for realistic simulations.
The document also discusses the communication aspects of the computation, detailing how processors interact during the computation process. This includes local sparse matrix-dense vector multiplication, which is crucial for optimizing performance in parallel computing environments.
Overall, the document outlines a significant advancement in the field of electromagnetic scattering analysis, providing a robust framework for simulating complex geometries and materials. The improved method not only enhances computational efficiency but also broadens the potential applications in various engineering and scientific domains. By facilitating more accurate and efficient simulations, this work contributes to the ongoing development of technologies that rely on electromagnetic scattering, paving the way for future innovations in the field.